

Whisper-WebUI 介绍
在人工智能日益融入我们生活的今天,语音解析技术正逐渐成为我们与机器交互的重要桥梁。近期,一款全新的全能语音解析模型及其Web界面实现——Whisper-WebUI,引起了广泛关注。这一技术的出现,不仅展现了AI在语音处理领域的最新成果,也为用户提供了更加便捷、高效的音频处理体验。
一、全能语音解析模型的魅力
这款全能语音解析模型凭借其广泛的训练数据和强大的多任务处理能力,成为了语音处理领域的一颗璀璨明珠。它的训练数据涵盖了各种音频资源,从日常对话到专业讲座,从新闻报道到娱乐节目,无所不包。这使得模型能够深刻理解各种语境下的语音特征,为后续的语音识别、翻译等任务奠定了坚实基础。
该模型不仅支持跨语言的语音识别,还能轻松应对语音翻译和语言种类辨别等复杂任务。无论是将英语演讲翻译成中文,还是识别一段法语对话中的关键词汇,它都能游刃有余地完成。这种多任务处理能力,使得该模型在实际应用中具有极高的灵活性和适应性。
二、Whisper-WebUI:让复杂技术触手可及
Whisper-WebUI是OpenAI为这款全能语音解析模型量身打造的网页界面。通过直观的HTML形式,用户无需深入了解复杂的编程知识,就能轻松驾驭这一强大模型。无论是转写录音、实时翻译音频,还是处理来自*******视频链接的音频,Whisper-WebUI都能提供一站式服务。
想象一下,你正在观看一个国外的技术讲座,但由于语言障碍,你无法完全理解讲座内容。这时,你只需将讲座链接粘贴到Whisper-WebUI中,选择相应的语言翻译选项,即可实时获取讲座的中文字幕。这一功能对于广大学习者来说,无疑是一大福音。
三、字幕生成与翻译的完美结合
Whisper-WebUI在字幕生成方面同样表现出色。它支持从多种来源生成字幕,包括音视频文件、*******链接以及麦克风实时输入。这意味着,无论你是在观看一部电影、听取一段演讲,还是进行实时对话,都能轻松获取准确的字幕。
此外,该工具还支持多种字幕格式,如SRT、WebVTT以及纯文本格式。这些格式兼容性强,可轻松导入到各种视频播放器和编辑软件中,为你的视频制作和编辑工作带来极大便利。
在翻译功能方面,Whisper-WebUI同样不容小觑。它不仅能将语音翻译成英语,还能利用Facebook的NLLB模型进行文本到文本的翻译。这一功能使得跨语言交流变得更加简单便捷,无论是观看外语电影、阅读国外新闻,还是与国外友人交流,都能轻松应对。
四、技术背后的力量
全能语音解析模型和Whisper-WebUI的成功背后,离不开深度学习技术的支持。通过大量的训练数据和先进的神经网络结构,模型能够捕捉到语音中的细微差别和上下文信息,从而实现高精度的语音识别和翻译。同时,Web界面的设计也充分考虑了用户体验,使得这些复杂的技术变得触手可及。
五、结语
全能语音解析模型和Whisper-WebUI的出现,无疑为语音处理领域注入了新的活力。它们以强大的功能和便捷的操作方式,满足了广大用户在语音识别、翻译和字幕生成等方面的需求。相信在未来的日子里,这些技术将继续为我们带来更多惊喜和收获。让我们拭目以待吧!
实际应用案例
让我们来看一个实际应用案例,以更好地了解Whisper-WebUI的强大功能。假设你是一名视频编辑师,需要为一段英文采访视频添加中文字幕。在没有Whisper-WebUI之前,你可能需要手动听写音频并逐句翻译,这无疑是一项繁琐且耗时的工作。
然而,现在有了Whisper-WebUI的帮助,你可以轻松完成这项任务。只需将采访视频的音频文件上传到Whisper-WebUI中,选择“英语”作为源语言,“中文”作为目标语言,然后点击“开始翻译”。短短几分钟后,你就可以得到一段准确的中文字幕文件。接下来,你只需将字幕文件导入到视频编辑软件中,即可轻松为视频添加字幕。
这个案例只是Whisper-WebUI众多应用场景中的一个缩影。无论是学习外语、观看国外电影、整理会议记录还是制作多语种字幕,Whisper-WebUI都能为你提供强大的支持。
技术挑战与未来发展
当然,全能语音解析模型和Whisper-WebUI在发展过程中也面临着一些技术挑战。例如,在处理不同口音、语速和背景噪音的语音时,模型的识别准确率可能会受到影响。此外,随着语言的不断发展和变化,模型也需要不断更新和优化以适应新的语言环境。
为了应对这些挑战并推动技术的持续发展,研究者们正在不断探索新的算法和技术手段。例如,利用深度学习技术来改进模型的泛化能力和抗噪性;通过引入更多的训练数据和优化模型结构来提高识别准确率;以及借助云计算和大数据技术来加速模型的训练和推理过程等。
可以预见的是,在未来的发展中,全能语音解析模型和Whisper-WebUI将会变得越来越智能、高效和便捷。它们将在语音识别、翻译和字幕生成等领域发挥更加重要的作用,为人们的生活带来更多便利和乐趣。同时,我们也期待着这些技术在教育、娱乐、医疗等更多领域的应用与拓展。
APISR 硬件及系统要求
系统:win10或win11系统,不支持win7及以下系统
内存:16G以上
显卡:8G以上
安装方法
想要体验Whisper-WebUI的强大功能吗?其实非常简单!首先,你需要访问一可软件,在页面下方找到下载按钮,下载并解压相关的代码。
解压完成后,双击“运行程序.exe”,等待一段时间之后会显示如下界面。
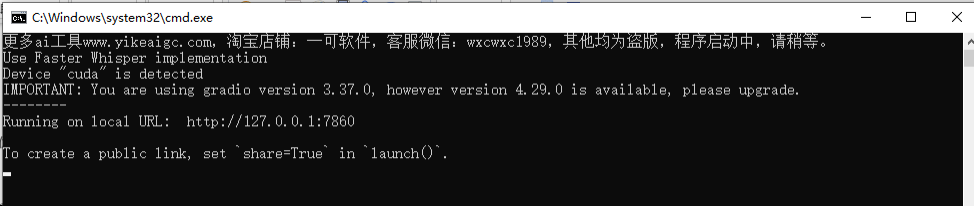
出现此界面说明运行成功。
在浏览器内输入:http://127.0.0.1:7860 即可打开webui页面(也就是主程序):
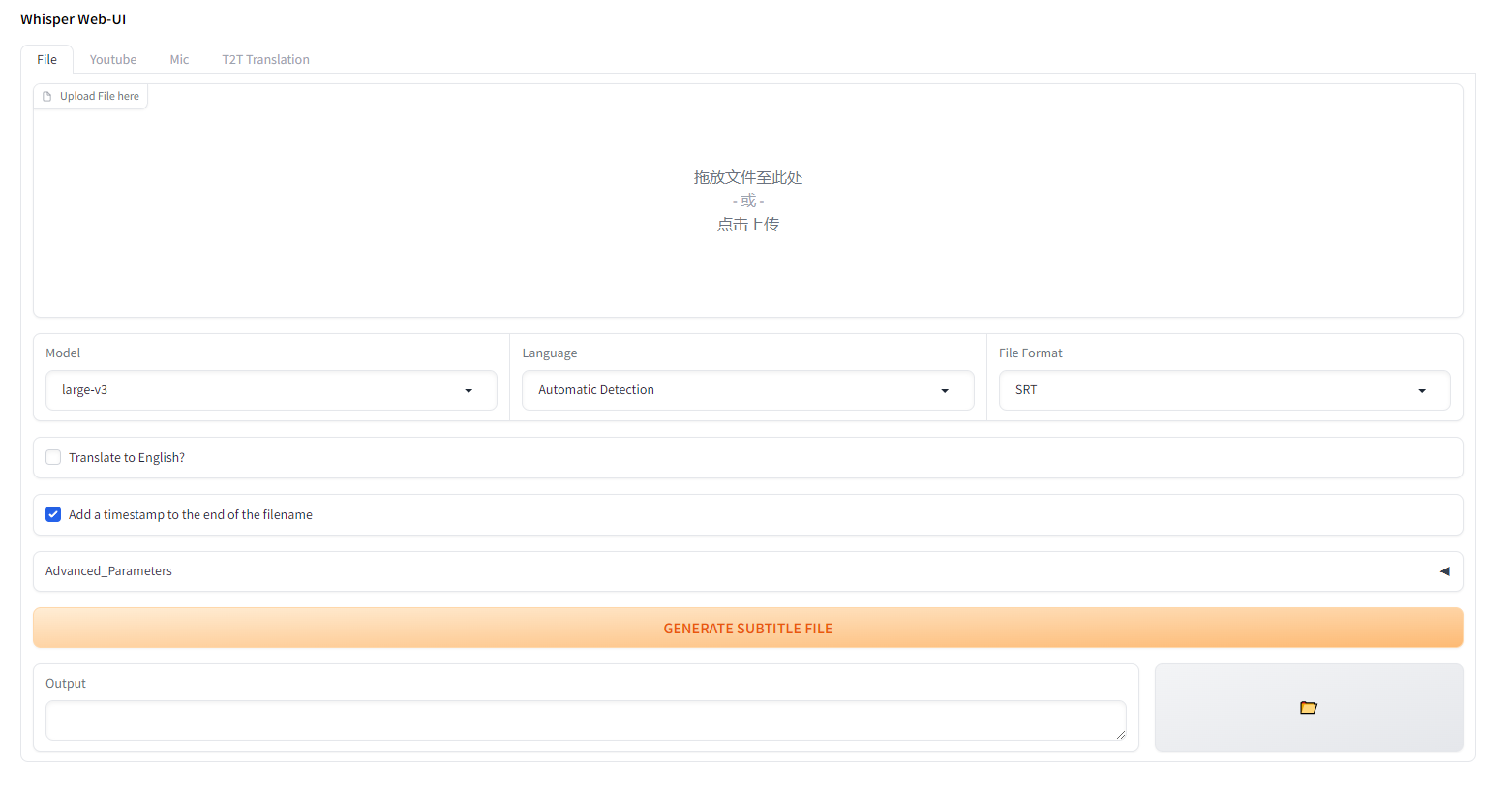
model选择large-v3,language选择automatic detection则为自动识别,或者下拉选择指定某国的语言。本工具目前支持80多个国家的语言。file format为输出文件的格式,txt或者srt(字幕格式)。
点击下面的GENERATE按钮,即可转换。速度由显卡决定,3060显卡为例:4分钟的视频需要几十秒左右。
txt translation 为翻译模式。
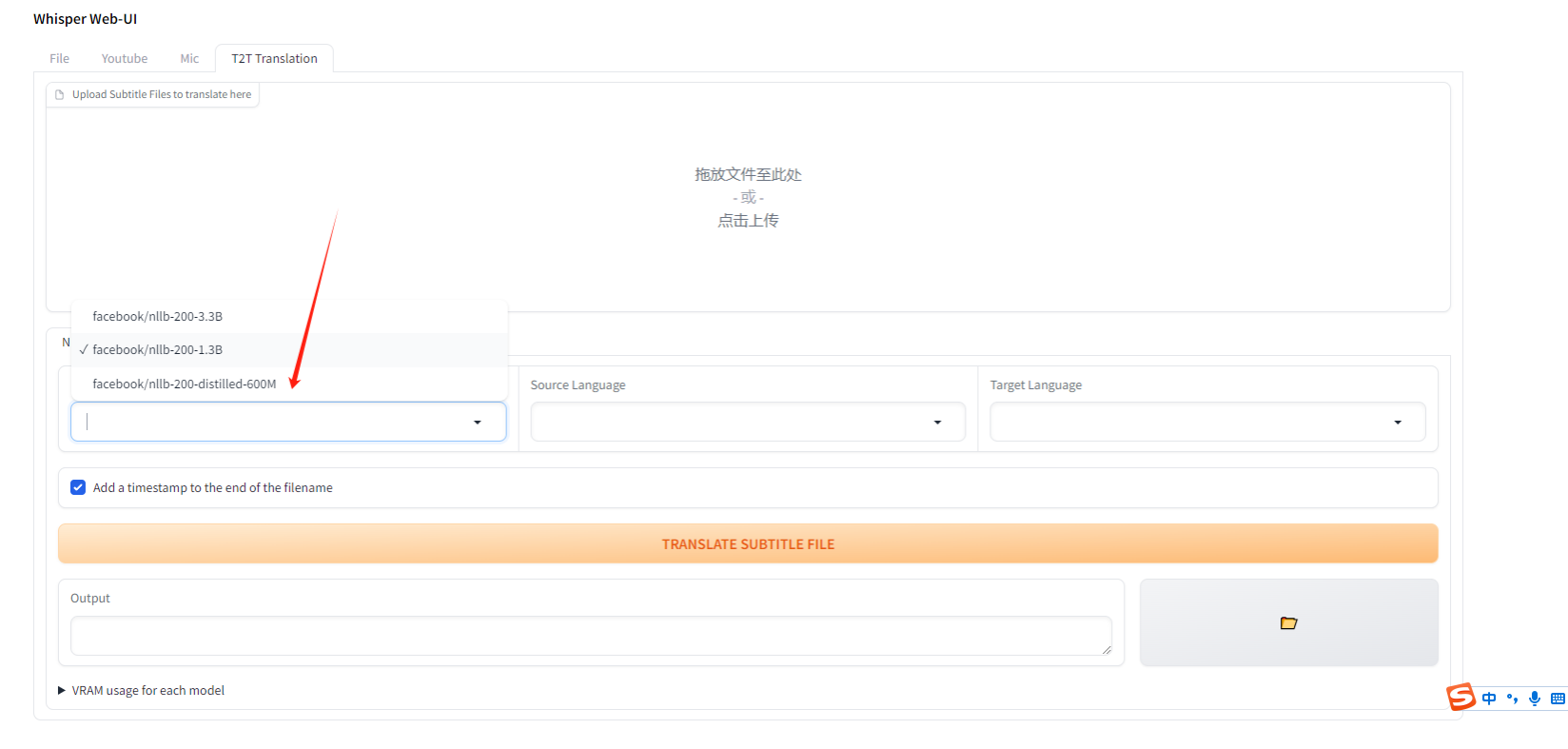
首次加载需要联网下载翻译模型,根据自己的显卡,选择合适的模型即可
Whisper-WebUI界面简洁直观,你可以轻松上传音频文件或者视频文件,或者直接通过麦克风进行实时语音识别。识别结果将迅速显示在界面上,供你查看和编辑。
如果你需要进行语音翻译,只需选择相应的源语言和目标语言,Whisper-WebUI将自动为你完成翻译工作。同时,你还可以将识别或翻译的结果导出为多种字幕格式,方便你在其他平台上使用。

下载说明:公众号搜索:“AI软件合集”,回复:“验证码”,获取查看下载地址及解压密码!
注意:本站汇聚全网顶级AI工具,全站内容仅对VIP开放;非VIP,下载后不能正常运行。
运行说明:先运行授权工具,登录VIP账号密码,然后运行即可。
注意:工具类直接运行,文档类需安装WPS,视频类需安装PotPlayer。