

ChatTTS 介绍
在AI技术飞速发展的今天,我们已经可以实现很多以前难以想象的事情。其中,AI音色克隆就是一项颇具神奇色彩的技术。基于GPT-SoVITS(一种基于生成对抗网络和Transformer的语音合成模型)的一键AI音色克隆,更是将这项技术推向了一个新的高度。
什么是GPT-SoVITS?
GPT-SoVITS是一个结合了生成对抗网络(GAN)和Transformer结构的先进语音合成模型。这个模型能够学习并模拟人类的声音特征,生成与原始音频高度相似的语音。而其中的“一键AI音色克隆”功能,更是让用户能够轻松地克隆出任何人的声音。
技术原理简述
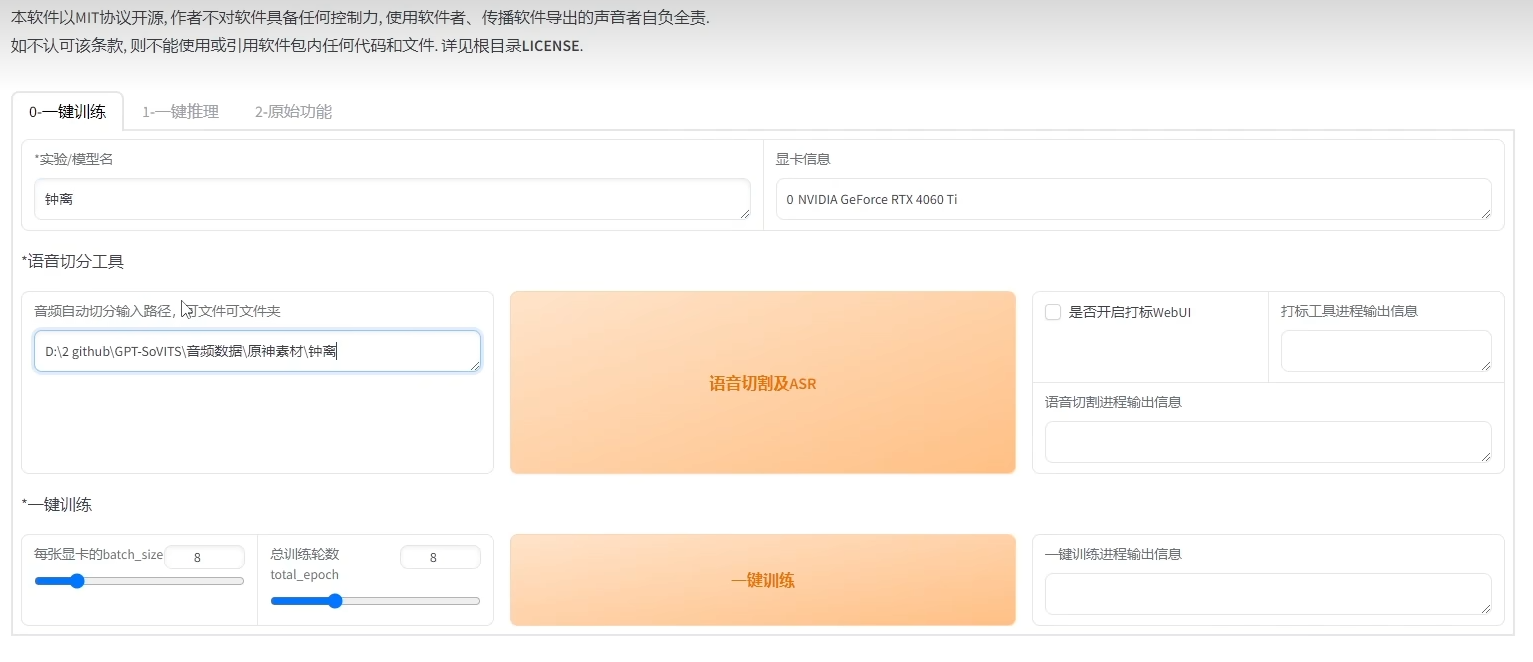
GPT-SoVITS模型的工作原理其实并不复杂。它首先通过大量的语音数据训练出一个基础的声音模型。当用户想要克隆某个特定人的声音时,只需要提供一段该人的语音样本,模型就能够从中提取出声音特征,并生成一个与该声音高度相似的新声音。
具体来说,GPT-SoVITS通过Transformer结构捕捉语音中的长期依赖关系,同时利用GAN的生成器和判别器进行对抗训练,不断优化生成语音的质量。这种结合使得GPT-SoVITS在音色克隆方面表现出了极高的准确性和自然度。
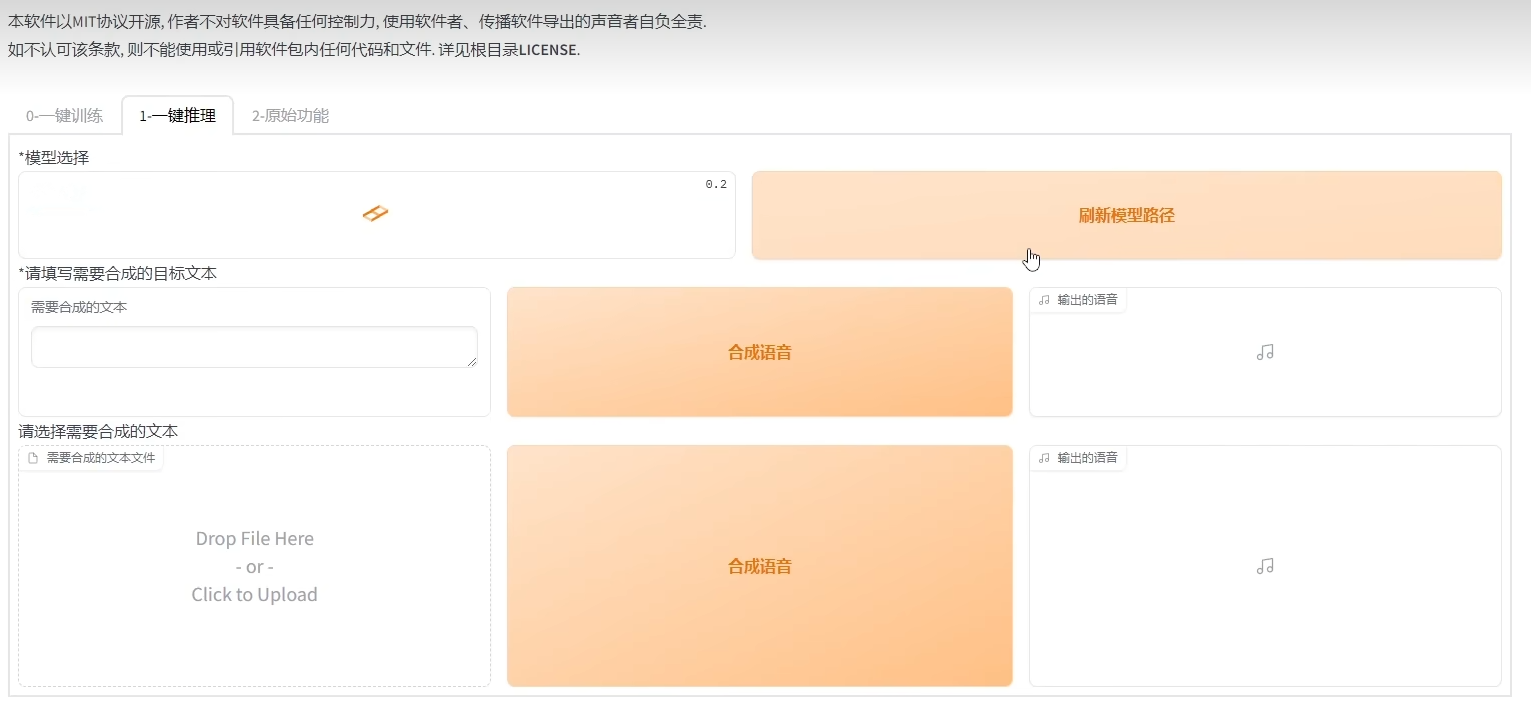
一键音色克隆的实现
实现一键音色克隆,首先需要对提供的语音样本进行预处理,提取出关键的声学特征,如基频、共振峰等。接着,GPT-SoVITS模型会根据这些特征调整其内部的参数,以匹配目标声音。
在实际操作中,用户只需上传一段目标人的语音样本到系统中,系统便会自动进行特征提取和模型调整。完成后,用户就可以通过简单的文本输入,生成与目标人声音相似的语音输出了。
技术挑战与解决方案
虽然GPT-SoVITS在音色克隆方面表现出色,但在实际应用中还是面临了一些技术挑战。比如,如何确保克隆出的声音既保持原始声音的特征,又足够自然流畅,这是一个关键问题。
为了解决这个问题,研究团队在模型训练中引入了多种损失函数,包括对抗性损失、重构损失和身份保持损失。这些损失函数共同作用,使得生成的语音在保持原始声音特征的同时,也更加自然和流畅。
应用场景展望
基于GPT-SoVITS的一键AI音色克隆技术有着广阔的应用前景。例如,在游戏和动画领域,这项技术可以用来为虚拟角色赋予独特而真实的声音,增强游戏的沉浸感和动画的观赏性。
在广告行业,通过音色克隆可以制作出更具个性化的广告语,从而提高广告的吸引力和效果。此外,在有声读物、语音助手等领域,这项技术也有着巨大的潜在应用价值。
真实案例分析
让我们来看一个具体的案例。某知名游戏公司想要为其新推出的一款游戏中的主角制作个性化的语音包。他们找到了一个声音极具特色的配音演员,录制了一段语音样本,并利用GPT-SoVITS模型进行音色克隆。
经过简单的操作,游戏公司就得到了与配音演员声音高度相似的声音模型。他们只需要将游戏中的对话文本输入到模型中,就可以生成与配音演员声音相似的游戏对话了。这不仅大大节省了配音成本,还为游戏增添了更多的个性化和真实感。
结语
基于GPT-SoVITS的一键AI音色克隆技术为语音合成领域带来了革命性的变革。它不仅提高了语音合成的质量和效率,还为各种应用场景提供了更多的可能性和创新空间。随着技术的不断进步和优化,我们有理由相信,这项技术将在未来发挥更加重要的作用。
